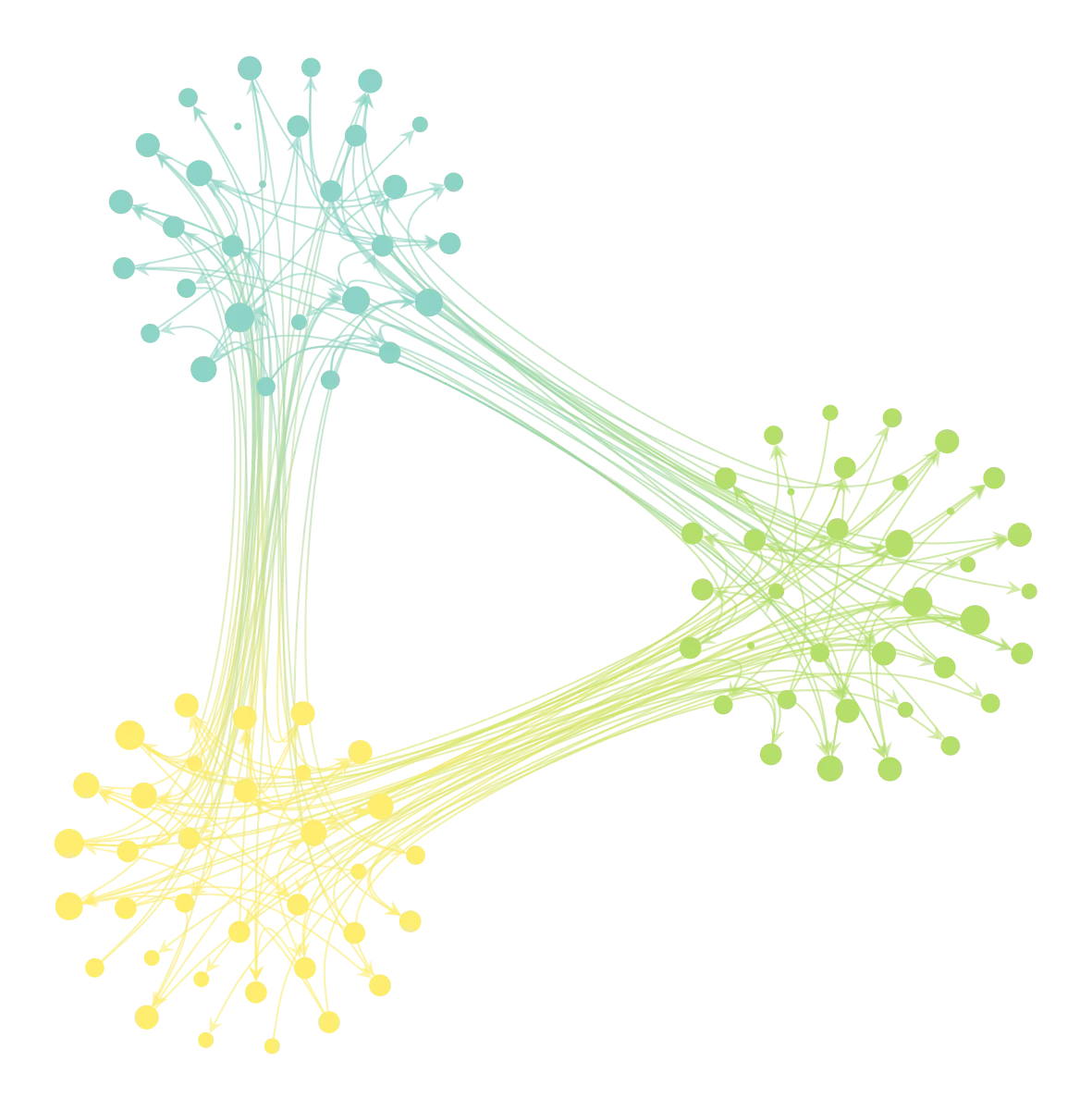
Growing networks with a given assortativity coefficient
Social interaction tends to happen primarily within groups: people usually talk, befriend, and mate mostly with others similar to themselves. Network scientists call this tendency assortativity, which in practice is often measured using a statistic called Newman’s assortativity coefficient (Newman 2003).1
Given a network divided into distinct social groups, define as the fraction of edges connecting nodes from group to group . By construction, we have that . Further, let represent the fraction of all edge endpoints attached to group , and similarly , which equals for undirected networks. Newman’s assortativity coefficient is then given by:
This quantity can be interpreted as a normalized correlation coefficient that ranges from (fully disassortative), through (no assortativity, random mixing), up to (fully assortative). It is a descriptive statistic that summarizes the group interactions in a given network.2
When setting up generative agent-based models (ABMs) to study social networks, we can thus describe a posteriori the degree of assortative mixing present in each sampled network; viewed that way, the ABM outputs samples of via intermediate ‘s.
Controlling
But what if we want to set the degree of assortativity in our simulations a priori? This is a common situation in ABMs; we’d like a simple knob to set and use it as an input to control network generation on the fly. This enables us to study the influence of assortativity on some other metric of interest . As a concrete example, Binder et al. (2022) find from U.S. Census data that the prevalence of interracial marriages strongly correlates with intergenerational social mobility. To study whether there is a causal connection, we could design an ABM with input (the assortativity of marriage interactions between races, where each race is a group) and output (some measure of intergenerational social mobility).
So how do we generate networks with prescribed values of ? Since ABMs are typically grown dynamically (edges are added or removed in time steps), we’d like an algorithm that produces networks that converge in time to a some given value of . More importantly, however, there are many different ways to do this (just think of the many different ways Nature produces assortative structure). We face design choices. What is the simplest possible way, without making unwarranted assumptions or imposing additional biases?
Well, the definition of given above assumes only the existence of groups with an edge fraction matrix that makes sense for our problem, so we start there. There are various algorithms for growing networks that converge to a given ,3 but we don’t know , only the projection , and there are many -matrices that project down to the same value of . If we can select “the least biased one”, call it , a practical and defensible solution to our problem presents itself:
given the target , use any algorithm to grow a baby network towards that “least biased” that gives rise to , and we have generated a network with a prescribed value of .
Choosing
A natural criterion for choosing comes from the principle of maximum entropy (ME) which dictates how to update probability assignments under newly received information (Jaynes 2003; Knuth and Skilling 2012; Giffin 2009). We can indeed interpret the edge fractions as probabilities4 such that specifies a probability mass distribution with two-dimensional index . Then it is a well known result that we can impose the assortativity constraint in the minimum constraining way possible — i.e., maximally noncomittal and minimally biased — by using the ME principle. This says that
given the target , we should choose out of all possible distributions that one distribution which has simultaneously maximum entropy and satisfies together with the normalization requirement .5
If think in terms of dimensionality, the ME principle pins down a unique inversion of a projection from a high-dimensional object down to a one-dimensional scalar . In the machine learning literature this is known as maximum entropy pdf projection. Baggenstoss (2018) notes that “if we always choose among models that have maximum possible entropy for the given choice of features, we are likely to obtain better features and better generative models”.
The favorable performance of ME models is due simply to the fact that entropy quantifies the number of ways a particular distribution can come about, so by maximizing it we select the most likely solution presented to use by Nature. Consider the following plot of the normalized entropy of a 1000 randomly generated matrices which all satisfy the constraints .

This illustrates two things: (1) many exist that satisfy the given constraints; (2) most of them lie near the maximum value . Those that do represent distributions most likely to come about by a non-opinionated generating mechanism, often whimsically represented by a team of monkeys throwing balls in equally-sized boxes (Sivia and Skilling 2006, sec. 5.2.1). (This is essentially how statistical physics models Nature.) Our task now is to locate that which attains .
Finding
Formally, with the discrete entropy defined as
we have the constrained optimization problem
For a small amount of groups we can solve this problem numerically. Using an heuristic ansatz, we then derive an analytical solution valid for any . Reproducible calculations are in this Pluto notebook.
Numerical solution
Constraining amounts just to a quadratic constraint, since
which is a quadratic constraint in the . Unfortunately, the problem is not a convex one, because the associated quadratic form is nondefinite (quadratic constraints are nonconvex, unlike quadratic inequalities). In other words, we cannot transform this entropy maximization problem into the exponential cone which would give us the global optimum.
Nevertheless, nothing stops us from looking for locally stationary points. The JuMP optimizer returns this solution for and , for example:
5×5 Matrix{Float64}:
0.096 0.026 0.026 0.026 0.026
0.026 0.096 0.026 0.026 0.026
0.026 0.026 0.096 0.026 0.026
0.026 0.026 0.026 0.096 0.026
0.026 0.026 0.026 0.026 0.096
Despite the fact that we assumed nothing about symmetry of , we get back very simple solutions that (1) are symmetric and (2) look like a linear combination of I = eye(n,n) and J = ones(n,n) matrices, which we exploit below. Note that this is still true for .
Heuristic solution
The heuristic says that be a convex combination of and (the identity and ones matrix), normalized such that . In other words,
with , the number of discrete classes and is the identity matrix and the all‑ones matrix. This heuristic linearly interpolates the solutions for two limiting cases:
- : edges spread uniformly over all group pairs (no assortativity)
- : all edges strictly within groups (perfect assortativity)
Now we can plug this in and solve for . This yields
such that
which is indeed the simplest possible form one would expect, and which agrees with the numerical solution obtained with JuMP shown above (and does so for any value of I could test numerically). The expressions for are constant: the sums along rows and columns always add up to ; whereas the trace does depend on .
Is this the global solution?
The entropy difference (Jaynes 2003, 287) of is given by
where is the maximum possible value of the entropy and . In general, the entropy difference quantifies the difficulty of generating valid candidate distributions, and therefore the strength of the applied constraints.

This last plot shows that for the heuristic solution is indeed optimal, since we have reached the maximum possible value of the entropy while satisfying the constraints.
The optimal ME solution is smooth in . If we assume that it is unique, then intuition suggests that our heuristic is in fact that unique solution, since it goes smoothly into the known optimal solution as . It is probably possible to show this rigorously: please reach out if you have an idea on how to do so!
Sampling vs. growing networks with a given
Now we have a defensible choice of given , we can use eg. the algorithm in (Newman 2003, sec. IIC) to sample a network that will tend to and therefore to asymptotically.
However, it might be more desirable to use a growing method, because this has the advantage that it can be used in an on-line fashion — growing networks by adding one or more edges per timestep, as is usually done in dynamical ABM simulations.6 A straightforward growing method is:
- Sample a pair
- Sample a node (agent) uniformly from group
- Sample a node (agent) uniformly from group
- Connect the two sampled nodes (agents) from steps 2 and 3
- Repeat for each timestep
This might be the simplest possible way to achieve this, and would be probably what one would come up with after a moment’s thought. And indeed, this algorithm is itself equivalent to a maximum entropy model known as the Poisson model (Peixoto 2020 A.1), which is a ME solution to the group-membership constraint. Therefore, we may eliminate another round of design choices when growing the interaction networks during our simulations.
Note that 0 is fully allowed. The method can thus be used to grow disassortative networks equally well as assortative networks. This might come in handy at times since “disassortativity [in degree] is the natural state for all networks” (Newman and Park 2003).
Conclusion
In ABM, design choices are unavoidable, but whenever possible we should make them according to the maximum entropy (ME) principle: constrain only what we genuinely know and remain agnostic about everything else.7
I proposed such an agnostic way to sample or grow assortative networks. This may be used in ABM simulations of social networks such as Mudd et al. (2022). Assortative networks are of great interest in the social sciences, as are questions of causality, and in investigating these murky waters our ABMs can do with every bit of bias removal the ME principle affords them.
Footnotes
-
Newman’s assortativity coefficient is widely across several areas of applied network science: for example in (i) social networks: marriage markets (Binder et al. 2022); (ii) epidemiology: studying HIV risk in function of assortative structure in sexual networks (Abuelezam et al. 2019); (iii) criminology: describing co-offending patterns (Grund and Densley 2012); (iv) neuroscience: measuring structural and functional connectivity assortativity in brain networks (Bassett and Sporns 2017); (v) bioinformatics: assessing topological organization of protein–protein and gene regulatory networks (Barabasi and Oltvai 2004); and (vi) complex systems as a whole: used as an explanatory variable or feature in link-prediction and network-evolution studies (Liben-Nowell and Kleinberg 2003). ↩
-
It should be mentioned at the outset that the assortativity coefficient is just a statistic and should only be used if its mathematical expression is judged appropriate for the job. In particular it should not be used for finding assortiative blocks of nodes in networks, as it is essentially a normalized version of the modularity which has been shown to be (extremely) misleading by Peixoto (2022). A good way to find and summarize assortative structure is eg. in Zhang and Peixoto (2020). ↩
-
For example, Newman (2003) gives two of these. ↩
-
Or more generally, quantities that are nonzero and are summable (Sivia and Skilling 2006; Knuth and Skilling 2012) ↩
-
There may be more solutions. An important case for which uniqueness can be shown is when the constraints are prescribed expectation values (called soft constraints). ↩
-
Ofcourse, growing methods can also sample ‘static’ networks by only looking at the last timestep. ↩
-
It has a nice converse too: if we find effects in our data unexplained by a ME model, that is definite proof that there are underlying forces present not attributable to chance (“probabilistic fluctuations”) alone, and which merit further investigation (a better model). This universal principle goes beyond modeling networks in the social sciences, where we’ve applied it here; in fact, ME inference was first applied in statistical physics by Gibbs in the 19th century, but the conceptual advancements to understand what exactly was being achieved took the likes of Jaynes (1957). ↩
Go to next post ▤ or ▥ previous post in research series.